정보 검색
"오늘의AI위키"의 AI를 통해 더욱 풍부하고 폭넓은 지식 경험을 누리세요.
1. 개요
정보 검색은 컴퓨터를 사용하여 정보를 찾는 기술과 관련된 분야이다. 1945년 버니바 부시의 아이디어에서 시작되어, 1950년대 자동화 시스템이 등장했다. 1990년대 웹 검색 엔진의 발전으로 대중화되었으며, 데이터 집합, 색인, 랭킹, 표현, 사용자 피드백 등의 요소로 구성된다. 정보 검색 모델에는 불리안, 벡터, 확률, 특징 기반 모델이 있으며, 검색 성능은 정밀도, 재현율, F-측정값으로 평가한다. 정보 검색 기술은 직접/간접 검색, 키워드/검색 언어/자연어/문서 입력 등 다양한 방식으로 분류되며, 디지털 도서관, 검색 엔진, 추천 시스템 등 광범위한 분야에 응용된다. 주요 학술 단체 및 컨퍼런스, 그리고 토니 켄트 스트릭스 상, 제러드 살톤 상, 카렌 스파크 존스 상 등이 정보 검색 분야의 발전에 기여하고 있다.
더 읽어볼만한 페이지
- 정보 검색 - 검색 엔진
검색 엔진은 사용자가 입력한 검색어에 따라 웹 정보를 찾아 순위를 매겨 보여주는 도구로, 다양한 형태의 검색어를 처리하고, 알고리즘을 통해 결과를 순위화하며, 검색 최적화 및 정보 편향 문제와 사용자 경험 향상이라는 과제를 안고 있다. - 정보 검색 - 최근접 이웃 탐색
최근접 이웃 탐색은 다차원 공간에서 주어진 질의와 가장 유사한 데이터를 찾는 최적화 문제로, 데이터 압축, 데이터 마이닝, 기계 학습 등 다양한 분야에서 활용되며, 효율적인 탐색을 위해 다양한 알고리즘이 개발되고 있고, 개인 정보 보호 및 데이터 편향성과 같은 윤리적 문제에 대한 고려도 중요해지고 있다. - 지식 생태계 - 검색 엔진
검색 엔진은 사용자가 입력한 검색어에 따라 웹 정보를 찾아 순위를 매겨 보여주는 도구로, 다양한 형태의 검색어를 처리하고, 알고리즘을 통해 결과를 순위화하며, 검색 최적화 및 정보 편향 문제와 사용자 경험 향상이라는 과제를 안고 있다. - 지식 생태계 - 대중 매체
대중 매체는 정보를 전달하고 사회적 여론을 형성하며 오락을 제공하는 등 다양한 기능을 수행하며, 인쇄, 방송, 인터넷 등 다양한 형태로 발전해왔지만, 상업주의, 가짜 뉴스, 정치적 편향성 등의 문제점과 비판을 받기도 한다. - 자연어 처리 - 정보 추출
정보 추출은 비정형 또는 반구조화된 텍스트에서 구조화된 정보를 자동으로 추출하는 기술로, 자연어 처리 기술을 활용하여 개체명 인식, 관계 추출 등의 작업을 수행하며 웹의 방대한 데이터에서 유용한 정보를 얻는 데 사용된다. - 자연어 처리 - 단어 의미 중의성 해소
단어 의미 중의성 해소(WSD)는 문맥 내 단어의 의미를 파악하는 계산 언어학 과제로, 다양한 접근 방식과 외부 지식 소스를 활용하여 연구되고 있으며, 다국어 및 교차 언어 WSD 등으로 발전하며 국제 경연 대회를 통해 평가된다.
2. 역사
정보를 검색하기 위해 컴퓨터를 사용한다는 아이디어는 1945년 버니바 부시가 디 애틀랜틱지에 기고한 '우리가 생각하는 대로'를 통해 대중화되었다.[22] 최초의 자동화 정보 검색 시스템은 1950~1960년대에 도입되었다.
1992년 미국 국방부는 미국 국립표준기술연구소(NIST)와 함께 텍스트 검색 컨퍼런스(Text Retrieval Conference, TREC)를 후원하였으며, 이것은 TIPSTER 텍스트 프로그램의 일부였다. 이 프로그램의 목적은 대규모 텍스트를 위한 텍스트 검색 방법론의 성능 측정에 필요한 제반 시설을 지원함으로써 정보 검색 관련 학계를 후원하는 것이었다. 이를 통해 매우 큰 말뭉치에 적용 가능한 확장성 높은 검색 방법에 대한 연구가 촉진되었다. 그리고 웹 검색 엔진의 등장으로 인해 이러한 대규모 검색 시스템에 대한 요구는 더욱 커지게 되었다.
한국 정보 검색 연구는 주로 학계와 정부출연연구소를 중심으로 이루어졌다. 1990년대 PC통신 시절 천리안, 하이텔 등에서 제한적인 정보 검색 서비스를 제공하기 시작하였다. 1990년대 후반, 심마니, 미스다찾니, 까치네 등 초기 한국형 검색 엔진들이 등장하였다. 2000년대 초, 네이버, 다음 등 포털 사이트들이 자체 검색 엔진을 개발하고 서비스를 고도화하면서 한국 정보 검색 시장을 주도하기 시작하였다.
2. 1. 초기 역사 (1940년대 ~ 1960년대)
컴퓨터를 사용하여 관련 정보를 검색한다는 아이디어는 1945년 버니바 부시가 발표한 논문 "우리가 생각할 수 있는 대로(As We May Think)"에서 대중화되었다.[7] 부시는 1920년대와 1930년대에 에마누엘 골드버그가 출원한 필름에 저장된 문서를 검색하는 '통계 기계' 특허에서 영감을 받았던 것으로 보인다.[8] 컴퓨터가 정보를 검색하는 최초의 설명은 1948년 홀름스트롬이 기술했는데,[9] 초기 유니박(Univac) 컴퓨터에 대한 언급을 자세히 설명했다. 자동 정보 검색 시스템은 1950년대에 도입되었으며, 1957년 로맨틱 코미디 영화 데스크 셋(Desk Set)에도 등장했다. 1960년대에는 제라드 살톤이 코넬 대학교에 최초의 대규모 정보 검색 연구 그룹을 설립했다. 1970년대까지는 크랜필드 컬렉션(수천 개의 문서)과 같은 소규모 텍스트 말뭉치에서 여러 가지 검색 기술이 효과적임이 입증되었다.[7] 록히드 다이얼로그 시스템과 같은 대규모 검색 시스템은 1970년대 초에 사용되기 시작했다.2. 2. 발전기 (1970년대 ~ 1980년대)
1970년대 초, 최초의 온라인 시스템인 NLM의 AIM-TWX, MEDLINE, 록히드의 다이얼로그(Dialog), SDC의 오비트(ORBIT)가 등장했다.[18][19] 1970년대까지 크랜필드 컬렉션(수천 개의 문서)과 같은 소규모 텍스트 말뭉치에서 여러 가지 검색 기술이 효과적임이 입증되었다.[7] 록히드 다이얼로그(Lockheed Dialog) 시스템과 같은 대규모 검색 시스템은 1970년대 초에 사용되기 시작했다.1971년, 니콜라스 자딘(Nicholas Jardine)과 코넬리스 J. 반 라이즈버겐(Cornelis J. van Rijsbergen)은 "정보 검색에서 계층적 클러스터링(hierarchic clustering)의 사용(The use of hierarchic clustering in information retrieval)"을 발표하여 "클러스터 가설(cluster hypothesis)"을 명확히 하였다.[14]
1975년에는 솔턴(Salton)의 세 가지 출판물에서 벡터 처리 프레임워크와 용어 구분(term discrimination) 모델을 완전히 명확히 하였다.
- ''색인 이론(A Theory of Indexing)'' (산업 및 응용 수학 학회)
- ''자동 텍스트 분석에서 용어 중요도 이론(A Theory of Term Importance in Automatic Text Analysis)'' (JASIS v. 26)
- ''자동 색인을 위한 벡터 공간 모델(A Vector Space Model for Automatic Indexing)'' (CACM 18:11)
1978년에는 최초의 ACM(Association for Computing Machinery) SIGIR(Special Interest Group on Information Retrieval) 회의가 열렸다.
1979년, C. J. 반 라이즈버겐(C. J. van Rijsbergen)은 ''정보 검색(Information Retrieval)''(Butterworths)을 발표했는데, 여기에는 확률적 모델이 중점적으로 다루어졌다. 같은 해, 타마스 도스코크스(Tamas Doszkocs)는 미국 국립 의학 도서관(National Library of Medicine)에서 MEDLINE을 위한 CITE 자연어 사용자 인터페이스(natural language user interface)를 구현하였다. CITE 시스템은 자유 형식 쿼리 입력, 순위가 매겨진 출력 및 관련성 피드백을 지원했다.[15]
2. 3. 도약기 (1990년대 ~ 현재)
1992년 미국 국방부는 미국 국립표준기술연구소(NIST)와 함께 텍스트 검색 컨퍼런스(Text Retrieval Conference, TREC)를 후원하였으며, 이것은 TIPSTER 텍스트 프로그램의 일부였다.[22] 이 프로그램의 목적은 대규모 텍스트를 위한 텍스트 검색 방법론의 성능 측정에 필요한 제반 시설을 지원함으로써 정보 검색 관련 학계를 후원하는 것이었다. 이를 통해 매우 큰 말뭉치에 적용 가능한 확장성 높은 검색 방법에 대한 연구가 촉진되었다. 그리고 웹 검색 엔진의 등장으로 인해 이러한 대규모 검색 시스템에 대한 요구는 더욱 커지게 되었다.1990년대부터 확산된 구글(Google)이나 야후(goo)와 같은 월드 와이드 웹 상의 데이터를 대상으로 하는 검색 엔진은 이전에는 실험용 IR 시스템에서만 볼 수 있었던 많은 기능을 구현하며 정보 검색의 대중화를 이끌었다.
2000년대 이후의 정보 검색 과제는 다음과 같이 요약할 수 있다.
- 이른바 딥 웹 (쇼핑 사이트 등을 대표하는, 백엔드의 대규모 데이터베이스가 동적인 콘텐츠를 생성하는 웹사이트)을 대상으로 한 검색
- 보다 직관적인 사용자 인터페이스
- 보다 인간에 가까운 고도의 판단 기준을 가진 멀티미디어 정보 검색
- 다양한 미디어를 통합적이고 횡단적으로 다루는 크로스미디어 정보 검색
- 저장되는 데이터나 검색 입력이 언어에 의존하지 않는 다국어(크로스 링구얼) 검색 환경
- P2P 네트워크 등의 대규모 분산 데이터를 대상으로 한 정보 검색
2. 4. 한국 정보 검색의 역사
한국 정보 검색 연구는 주로 학계와 정부출연연구소를 중심으로 이루어졌다. 1990년대 PC통신 시절 천리안, 하이텔 등에서 제한적인 정보 검색 서비스를 제공하기 시작하였다. 1990년대 후반, 심마니, 미스다찾니, 까치네 등 초기 한국형 검색 엔진들이 등장하였다. 2000년대 초, 네이버, 다음 등 포털 사이트들이 자체 검색 엔진을 개발하고 서비스를 고도화하면서 한국 정보 검색 시장을 주도하기 시작하였다. 최근에는 인공지능, 빅데이터 기술을 활용한 지능형 검색, 개인화된 맞춤형 검색 서비스가 발전하고 있다.3. 정보 검색 요소
현대 정보 검색 시스템은 크게 데이터 집합, 색인, 랭킹, 표현, 사용자 피드백의 다섯 가지 요소로 구성된다.
- '''데이터 집합'''은 검색 대상이 되는 데이터로, DB형 데이터와 문서형 데이터로 나뉜다.
- '''색인'''은 문서형 데이터 집합에서 각 단어별 문서 목록을 생성한 것으로, 역문서 리스트라고도 한다.
- '''랭킹'''은 입력된 질의에 대해 가장 적합한 순서로 문서를 나열하는 작업이다.
- '''표현'''은 검색 결과를 사용자에게 제시하는 방식을 의미한다.
- '''사용자 피드백'''은 검색 품질 개선에 활용되는 정보이다.
정보 검색은 데이터베이스, 자연어 처리, 계산 언어학, 신호 처리, 인지 심리학을 배경으로 하는 패턴 인식, 도서관 정보학, 수학 등 다양한 요소 기술의 조합으로 이루어져 있다.[2] 정보 검색 시스템은 이러한 정보 검색을 실현하기 위한 소프트웨어 및 하드웨어로 구성되는 시스템이다.
정보 검색 시스템은 주로 '''데이터베이스''', '''검색 대상 데이터''', '''메타데이터(색인어)''', '''사용자 인터페이스''', '''검색 알고리즘''' 등으로 구성된다.
'''데이터베이스'''는 '''검색 대상 데이터'''를 축적하고 관리하며, '''검색 대상 데이터'''로부터 생성된 '''메타데이터'''도 저장한다. 검색 이용자는 '''사용자 인터페이스'''를 통해 검색어(검색 문)를 입력하여 검색을 실행하고, '''검색 알고리즘'''은 '''데이터베이스'''에 저장된 '''메타데이터'''에서 적절한 데이터를 선택하여, 선택된 '''메타데이터'''에 해당하는 '''검색 대상 데이터'''를 '''사용자 인터페이스'''를 통해 이용자에게 응답한다.
예를 들어 웹사이트의 정보 검색에서는, 각 웹사이트의 내용이 검색 대상 데이터이고, 웹사이트 내용의 요약이나 키워드, 소개글이 메타데이터이며, 검색 엔진이 사용자 인터페이스와 검색 알고리즘에 해당한다. 검색 엔진은 검색 키워드와 일치하는 메타데이터를 데이터베이스에서 선택하여, 선택된 메타데이터에 해당하는 검색 대상 데이터를 검색 결과에 표시한다.
3. 1. 데이터 집합
검색의 대상이 되는 데이터는 크게 DB형 데이터와 문서형 데이터로 구분된다. DB형 데이터는 날씨, 주가, 기차시간표 등과 같이 일정한 스키마를 갖고 DB에 저장되어 있는 데이터인 반면, 문서형 데이터는 제목과 본문, 생성날짜 등으로 구성된 데이터를 말한다.[20] 문서형 데이터는 다시 정형적 문서형 데이터와 비정형적 문서형 데이터로 나뉘는데, 정형적 문서형 데이터는 지식검색 데이터나 블로그 데이터와 같이 비교적 나름대로의 서식을 갖추고 있는 데이터이고, 비정형적 문서형 데이터는 웹문서와 같이 상대적으로 자유로운 형식의 데이터를 의미한다.[20]3. 2. 색인
색인은 문서형 데이터 집합에 대하여, 각 단어별 문서 리스트를 생성한 것을 의미하며, 흔히 역문서 리스트(inverted list)라는 용어로도 표현된다.[1] 색인 방식에 따라 데이터 집합을 한꺼번에 색인하는 일괄 색인(batch indexing)과 점증 색인(incremental indexing)으로 구분될 수 있는데, 뉴스 검색은 대표적으로 점증 색인을 적용하는 분야이다.[1] 정보 검색을 위한 색인 과정에서 중요한 것은 주어진 문서에서 색인어를 추출하는 과정인데, 언어적 특성과 상관없이 적용될 수 있는 n-gram 방식과, 자연언어처리의 형태소 분석을 통한 방식이 존재한다.[1]3. 3. 랭킹
랭킹(ranking)은 입력된 질의(query)에 대하여 가장 적합한 순으로 문서형 데이터들을 나열하는 작업을 의미하며, 이를 위한 다양한 검색 알고리즘들이 존재한다. 여기서 적합성(relevance)은 질의와 문서와의 유사성(similarity), 문서의 최신성(freshness), 문서 고유의 품질(quality), 그리고 사용자 검색 로그를 포함한 기타 여러 정보가 적절히 혼합되어 판단될 수 있다. 페이지랭크는 질의와는 상관없이 문서 고유의 품질을 문서 간의 링크 관계에 따라 규정하는 대표적인 품질 측정 알고리즘이라 할 수 있다.3. 4. 표현
검색 결과는 구글과 같이 단순 리스트 형식으로 사용자에게 제시될 수도 있고, 유사한 결과들이 그룹화되어 제시될 수도 있으며, 데이터의 종류(이미지, 블로그, 웹문서) 등으로 구분지어 제시될 수도 있다.3. 5. 사용자 피드백
사용자 피드백은 검색의 품질을 개선하는 데 활용되는 정보이다. 사용자가 직접 검색 결과에 피드백을 주는 명시적 피드백(explicit feedback)과 사용자의 검색 행위를 기록해 놓은 검색 로그가 대표적인 암묵적 피드백(implicit feedback)으로 구분될 수 있다. 최근에는 암묵적 피드백 정보를 활용하여 검색 결과를 개선하려는 연구가 활발히 진행되고 있다.4. 정보 검색 모델
정보 검색 모델에는 불리안 모델, 벡터 모델 등이 있다. 정보 검색 모델은 관련 문서를 효과적으로 검색하기 위해 문서를 적절한 형태로 변환하는 데 사용된다. 각 검색 전략은 문서 표현을 위해 특정 모델을 통합한다. 정보 검색 모델은 수학적 기반과 모델의 특성이라는 두 가지 차원으로 분류할 수 있다.[23][24]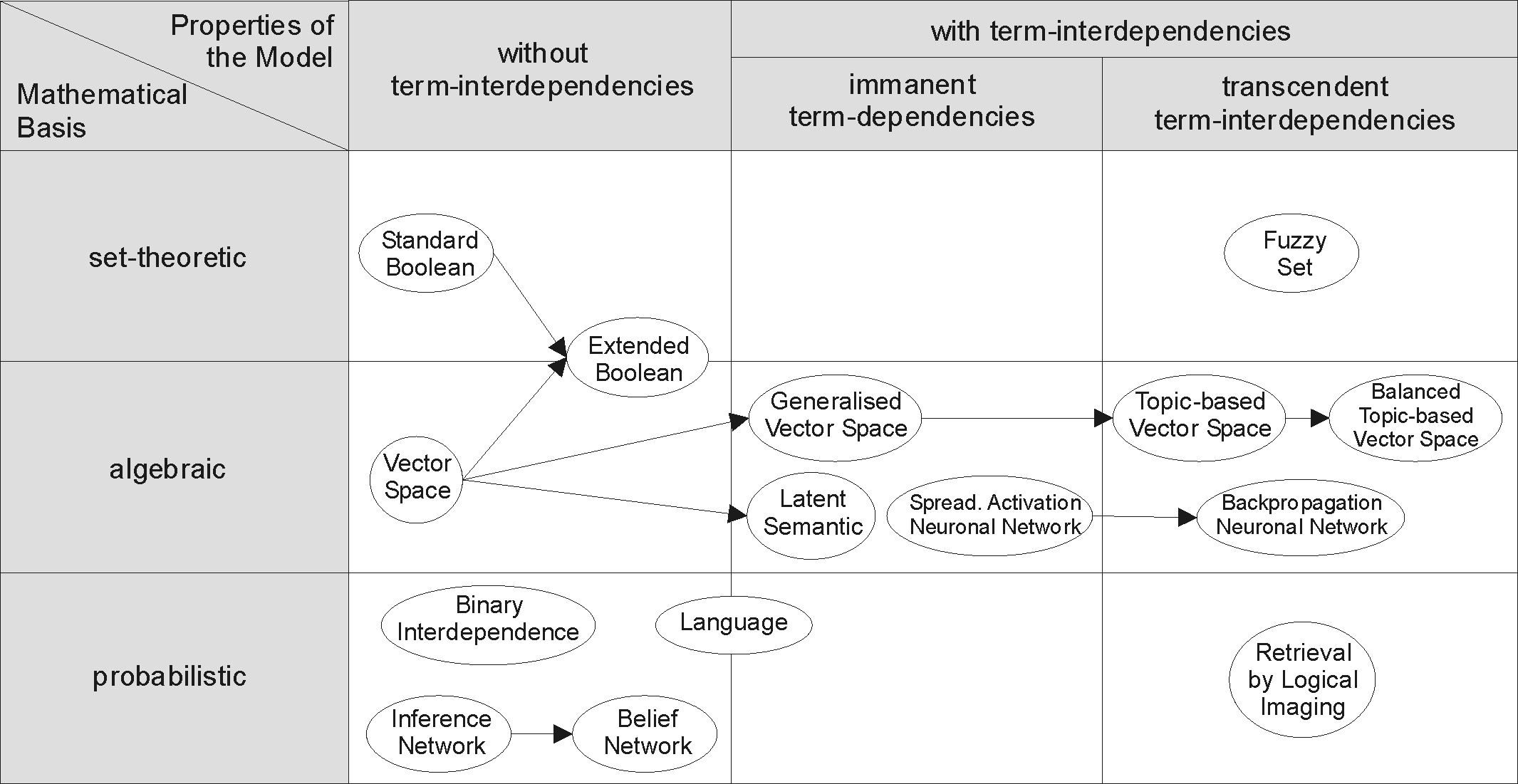
4. 1. 불리안 모델 (Boolean Model)
불리안 모델은 질의어에 있는 두 개 이상의 키워드를 and, or, not으로 연결하여 논리곱의 합 형태로 변환하고, 각 논리곱이 문서에 존재하는지 확인하는 방법이다.[23][24]4. 2. 벡터 모델 (Vector Model)
벡터 모델은 질의어와 각각의 문서를 모든 색인어에 대한 벡터 형태로 나타낸 후, 질의어와 각 문서의 벡터곱을 유사도로 이용하여 문서들을 랭킹하는 방법이다.[23][24]4. 3. 확률 모델 (Probabilistic Model)
확률 모델은 문서 검색 과정을 확률적 추론으로 취급한다. 주어진 질의에 대해 문서가 관련될 확률을 계산하며, 이때 베이즈 정리 등이 사용된다.4. 4. 특징 기반 검색 모델 (Feature-based Retrieval Model)
정보 검색 전략을 통해 관련 문서를 효과적으로 검색하기 위해, 문서는 일반적으로 적절한 형태로 변환된다. 각 검색 전략은 문서 표현을 위해 특정 모델을 통합한다. 오른쪽 그림은 몇몇 일반적인 모델의 관계를 보여준다. 그림에서 모델은 수학적 기반과 모델의 특성이라는 두 가지 차원에 따라 분류된다.
5. 정보 검색 성능 평가
정보 검색 시스템의 성능은 시스템이 사용자의 정보 요구를 얼마나 잘 충족하는지 평가하는 과정이다. 일반적으로 측정은 검색할 문서 집합과 검색 쿼리를 고려하며, 정밀도와 재현율이 대표적인 평가 지표이다.[1] 모든 측정은 관련성에 대한 기준 진실 개념을 가정한다. 즉, 모든 문서는 특정 쿼리와 관련이 있거나 없다고 알려져 있다.[1]
5. 1. 정밀도 (Precision)
정보 검색 시스템의 평가는 시스템이 사용자의 정보 요구를 얼마나 잘 충족하는지 평가하는 과정이다. 일반적으로 측정은 검색할 문서 집합과 검색 쿼리를 고려한다. 불리언 검색을 위해 설계된 기존 평가 지표에는 정밀도와 재현율이 포함된다. 모든 측정은 관련성에 대한 기준 진실 개념을 가정한다. 즉, 모든 문서는 특정 쿼리와 관련이 있거나 없다고 알려져 있다. 실제로 쿼리는 잘못 제기된 것일 수 있으며, 관련성에는 다양한 정도가 있을 수 있다.5. 2. 재현율 (Recall)
전체 관련 문서 중 실제로 검색된 문서의 비율이다. 재현율은 다음과 같이 계산한다.`재현율 = (검색된 관련 문서 수) / (전체 관련 문서 수)`
5. 3. F-측정값 (F-measure)
F-측정값은 정밀도와 재현율의 조화 평균으로 계산된다. F-측정값 공식은 다음과 같다.: ''F''-측정값 = 2 * (정밀도 * 재현율) / (정밀도 + 재현율)
정밀도와 재현율이 모두 높을수록 F-측정값도 높아진다.
6. 정보 검색 기술의 분류
정보 검색은 데이터베이스, 자연어 처리, 계산 언어학, 신호 처리, 패턴 인식, 도서관 정보학, 수학, 알고리즘 등 다양한 분야의 기술을 기반으로 한다. 이러한 기술들을 활용하여 소프트웨어 및 하드웨어로 구성되는 시스템이 '''정보 검색 시스템'''이다.[1]
정보 검색 기술은 검색 대상 데이터의 추상도 및 검색 입력의 종류에 따라 분류할 수 있다.
6. 1. 검색 대상 데이터의 추상도
직접 검색은 메타데이터를 거치지 않고 데이터 자체를 직접 처리하는 검색 방법이다. 예를 들어 해밍 거리를 이용하여 입력된 음정과 유사한 음정의 음악을 검색하는 방법이 있다. 실제로는 전처리로서 색인 생성을 미리 수행하는 방식이 많지만, 이러한 경우에도 데이터에 포함된 표현을 그대로 사용하여 검색을 수행하기 때문에 검색 모델로서는 직접 검색으로 분류된다.[1]전문 검색은 직접 검색의 한 종류이며, 문서 데이터의 전문을 자동 처리 방식으로 스캔하여 메타데이터를 생성하고 저장하여, 검색 입력과 일치하는 데이터를 검색 결과로 하는 검색 방법이다. "전문 검색 시스템 Namazu"나 "아파치 솔러(Apache Solr)" 등이 사용되고 있다.[1]
간접 검색은 데이터베이스에 축적된 데이터에서 메타데이터를 생성하여 저장하고, 검색 입력이 이루어졌을 때 내부 표현으로 변환된 검색 입력과 저장된 메타데이터를 비교하여 검색 결과를 생성하는 검색 방법이다.[1]
6. 2. 검색 입력의 종류
- 단어(키워드): 단어를 지정하여 검색하는 방법으로, 가장 일반적인 검색 방식이다. 검색하고자 하는 키워드를 입력한 후 검색을 실행하거나, 한 글자씩 입력할 때마다 검색이 이루어지는 증분 검색 방식이 널리 사용된다. 검색어와 함께 유사 검색, 날짜 특정, 와일드카드 등 다양한 검색 옵션을 활용할 수 있다.
- 검색 언어: 시스템 고유의 검색 언어를 사용하여 검색하는 방법이다. 논리합, 논리곱 등의 부울 논리 연산을 사용하여 검색 범위를 좁힐 수 있다. 주로 연구자, 법률, 의학 등 특정 분야 전문가를 대상으로 하는 검색 시스템에 사용된다. SQL과 같은 표준 데이터베이스 질의어를 사용하거나, IEEE Xplore와 같이 특정 검색 엔진 고유의 검색 언어를 사용하기도 한다.
- 직접 입력: 이미지, 콧노래 등 관련 데이터를 직접 입력하여 검색하는 방법이다. 예를 들어, 얼굴 인식 시스템이나 Google 이미지 검색처럼 특정 이미지를 입력하여 유사한 이미지를 찾거나, 콧노래를 입력하여 관련 음악을 검색하는 방식이다. 패턴 인식 기술과 밀접하게 관련되어 있다.
- 자연어: 자연스러운 문장 형태로 질의하는 방법이다. 구글 랩의 "일본어 자연어 검색"과 같이 대형 검색 엔진에서도 자연어 검색을 제공하는 사례가 있다.
- 문서: 문서 자체를 입력하여 유사한 문서를 검색하는 방법으로, 예시에 의한 질의(Query by Example)라고도 한다. 멀티미디어 문서 검색에서 주로 사용된다.
7. 정보 검색 알고리즘
정보 검색에는 여러 가지 알고리즘이 제안되었다. 대표적인 알고리즘은 다음과 같다.[1]
일반적으로 정보 검색 시스템을 구축할 때 메타데이터 생성 시 색인을 동시에 생성하고, 검색 알고리즘에 의한 검색 결과 평가 시 색인을 이용한 최적화를 수행한다.[1]
7. 1. 패턴 매칭 (Pattern Matching)
검색 질문으로 입력된 표현을 그대로 포함하는 문서를 검색하는 알고리즘이다. 단순히 패턴만 찾는 것이 아니라, 활용 형태의 변화에 의한 동의어의 패턴 불일치를 해소한 검색을 수행하는 등의 확장이 자주 이루어진다.[1] 패턴 매칭 자체의 자세한 알고리즘은 문자열 탐색을 참조한다.[1]7. 2. 불 논리 (Boolean Logic)
패턴 매칭 검색에 더해, 메타데이터의 속성별 필터링 조건을 논리곱, 논리합 등으로 조합하여 병용하는 검색 방법이다.7. 3. 벡터 공간 모델 (Vector Space Model)
키워드 등을 각 차원으로 설정한 고차원 벡터 공간을 상정하고, 검색 대상 데이터나 사용자 검색 질문을 벡터로 변환한다. 벡터 공간상에 검색 대상 벡터를 배치하고, 벡터화된 검색 질문과 데이터 벡터 간 상관량(코사인, 내적, 유클리드 거리 등이 사용됨)을 계산하여 검색 대상 데이터와 검색 질문 간 관계 강도를 파악하는 모델이다.- 잠재 의미 색인(잠재 의미 분석, LSI): 벡터 공간 모델 응용 알고리즘. 고차원 벡터 공간을 행렬로 취급, 특이값 분해를 수행하여 얻어진 직교 저차원 벡터 공간상에서 검색을 수행한다. 동의어 문서 간 관련성을 반영하고 검색 대상 데이터 내용 편향에 덜 영향받는 검색이 가능하다.
8. 정보 검색 응용 분야
정보 검색 기술은 매우 다양한 분야에서 활용되고 있다. 일반 응용 분야, 미디어 검색 분야, 검색 엔진 분야, 특정 도메인 응용 분야, 정보 검색 기법 활용 방법/기술 등으로 나눌 수 있다.
- 일반 응용 분야
- 디지털 도서관
- 정보 필터링
- 추천 시스템
- 미디어 검색 분야
- 블로그 검색
- 이미지 검색
- 3D 검색
- 음악 검색
- 뉴스 검색
- 음성 검색
- 비디오 검색
- 검색 엔진 분야
- 사이트 검색
- 데스크톱 검색
- 기업 검색
- 연합 검색
- 모바일 검색
- 소셜 검색
- 웹 검색
- 특정 도메인 응용 분야
- 전문가 검색
- 유전체 정보 검색
- 지리 정보 검색
- 화학 구조 정보 검색
- 소프트웨어 공학 정보 검색
- 법률 정보 검색
- 수직 검색
- 정보 검색 기법 활용 방법/기술
- 적대적 정보 검색
- 자동 요약
- 다중 문서 요약
- 복합어 처리
- 다국어 정보 검색
- 문서 분류
- 스팸 필터링
- 질의응답[1]
8. 1. 일반 응용 분야
- 디지털 도서관
- 정보 필터링
- 추천 시스템
- 미디어 검색
- 블로그 검색
- 이미지 검색
- 3D 검색
- 음악 검색
- 뉴스 검색
- 음성 검색
- 비디오 검색
- 검색 엔진
- 사이트 검색
- 데스크톱 검색
- 기업 검색
- 연합 검색
- 모바일 검색
- 소셜 검색
- 웹 검색
8. 2. 특정 도메인 응용 분야
정보 검색 기술이 사용되는 분야는 다음과 같다.[1]
8. 3. 기타 검색 방법/기술
다음은 정보 검색 기술이 사용되는 방법/기술이다.9. 주요 학술 단체 및 컨퍼런스
정보 검색 분야의 주요 학술 단체 및 컨퍼런스는 한국과 국제로 나누어 볼 수 있다.
- 한국의 주요 학술 단체 (하위 섹션 참고)
- 국제 주요 학술 단체 및 컨퍼런스 (하위 섹션 참고)
9. 1. 한국
요약에 제시된 내용을 바탕으로, 원본 소스에서 한국 관련 연구회 정보를 추출하여 나열한다.이 출력은 다음 사항을 준수한다.
- 본문만 출력: 섹션 제목이나 추가 설명 없이 본문만 출력되었다.
- 위키텍스트 형식 준수: 외부 링크 문법을 정확히 사용했다.
- 한국어: 한국어로 작성되었다.
- 자료 분석: 원본 소스에서 주어진 섹션 제목과 요약에 해당하는 내용만 추출했다.
추가적인 수정은 필요하지 않다.